【案例】主从替换之后的复制风暴
本文共 2869 字,大约阅读时间需要 9 分钟。
一 现象 一套MySQL主-备-备-备数据库,其中的备库升级到主库之后,系统监控报警 Seconds_Behind_Master 瞬间为0,瞬间为数十万秒。第一感觉是遇到了复制风暴--不同于主备server_id 的log event在主备库之间无限循环复制。升级的逻辑图如下: 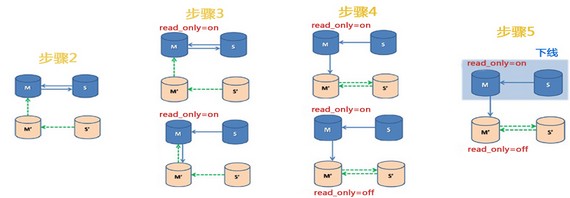 二 分析 在双主复制结构中,主库发生数据更新,会将更新记录为含有server_id_1 的log event事件发送到备库,然后备库更新数据,将含有server_id_1的log event 事件发送给主库,因此最初主库上的log event 更新事件又传了回来,这时候MySQL就要对复制事件的server_id进行判断,发现复制事件的server_id和自己的server_id相同时,放弃执行,如果不同 则执行该log event 并记录到binlog 里面继续发送给备库。 如果该event的server_id和主备的server_id都不相同,该log event 则在主备库中无限循环执行,也就是通常所说的复制风暴。 那为什么slave lag 为时大时小呢? 首先我们要了解MySQL 对于slave lag 的计算方式(sql/slave.cc ) 解释如下: long_time_diff就是seconds_behind_master seconds_behind_master= slave系统时间 - master执行创建event的timestamp - ( slave系统时间 - master系统时间 ) (slave系统时间-master执行最新event的timestamp):得到最新event到slave执行还要多久。 (slave系统时间-master系统时间):可能存在主备系统时间差别,所以计算seconds_behind_master要减去,但实际情况,slave和master系统时间基本一致,得到结果应该接近0 所以seconds_behind_master的值是由于slave系统时间-master执行最新event的timestamp 决定的,当导致循环复制的log event创建时间越久远,slave lag 会越大,执行完 这个event,会执行真正主库执行的log event ,此时slave lag 就会变成0 。 三 解决 查看新主库的server_id
二 分析 在双主复制结构中,主库发生数据更新,会将更新记录为含有server_id_1 的log event事件发送到备库,然后备库更新数据,将含有server_id_1的log event 事件发送给主库,因此最初主库上的log event 更新事件又传了回来,这时候MySQL就要对复制事件的server_id进行判断,发现复制事件的server_id和自己的server_id相同时,放弃执行,如果不同 则执行该log event 并记录到binlog 里面继续发送给备库。 如果该event的server_id和主备的server_id都不相同,该log event 则在主备库中无限循环执行,也就是通常所说的复制风暴。 那为什么slave lag 为时大时小呢? 首先我们要了解MySQL 对于slave lag 的计算方式(sql/slave.cc ) 解释如下: long_time_diff就是seconds_behind_master seconds_behind_master= slave系统时间 - master执行创建event的timestamp - ( slave系统时间 - master系统时间 ) (slave系统时间-master执行最新event的timestamp):得到最新event到slave执行还要多久。 (slave系统时间-master系统时间):可能存在主备系统时间差别,所以计算seconds_behind_master要减去,但实际情况,slave和master系统时间基本一致,得到结果应该接近0 所以seconds_behind_master的值是由于slave系统时间-master执行最新event的timestamp 决定的,当导致循环复制的log event创建时间越久远,slave lag 会越大,执行完 这个event,会执行真正主库执行的log event ,此时slave lag 就会变成0 。 三 解决 查看新主库的server_id  查看新备库的server_id
查看新备库的server_id  主库上冲突的事务的server_id
主库上冲突的事务的server_id  备库上冲突事务的server_id
备库上冲突事务的server_id 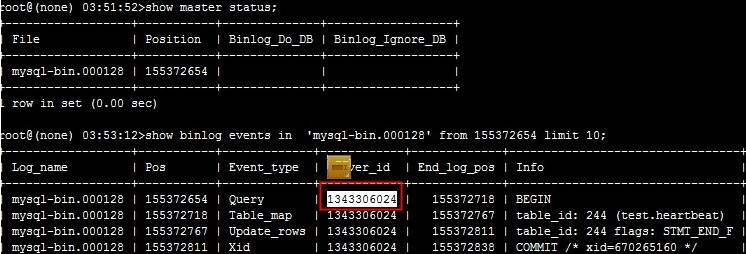 老的主库的server_id
老的主库的server_id 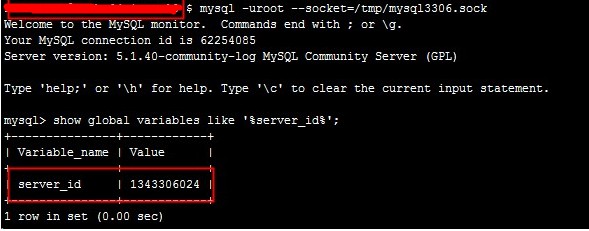 解决方法 在新的备库更改server_id为冲突数据的server_id,等数据耗完毕,server_id改为原库的server_id。 读者朋友可以思考一下为什么在备库上执行更改server_id的操作?
解决方法 在新的备库更改server_id为冲突数据的server_id,等数据耗完毕,server_id改为原库的server_id。 读者朋友可以思考一下为什么在备库上执行更改server_id的操作? 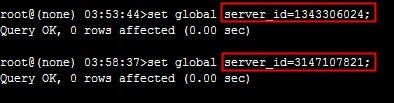 对于MySQL 本身,可以加上一层判断,在复制结构中检查 log envent的server_id是否属于 复制结构中数据库的server_id,如果不是,则判断该事物属于复制风暴事物,予以抛弃 。
对于MySQL 本身,可以加上一层判断,在复制结构中检查 log envent的server_id是否属于 复制结构中数据库的server_id,如果不是,则判断该事物属于复制风暴事物,予以抛弃 。
二 分析 在双主复制结构中,主库发生数据更新,会将更新记录为含有server_id_1 的log event事件发送到备库,然后备库更新数据,将含有server_id_1的log event 事件发送给主库,因此最初主库上的log event 更新事件又传了回来,这时候MySQL就要对复制事件的server_id进行判断,发现复制事件的server_id和自己的server_id相同时,放弃执行,如果不同 则执行该log event 并记录到binlog 里面继续发送给备库。 如果该event的server_id和主备的server_id都不相同,该log event 则在主备库中无限循环执行,也就是通常所说的复制风暴。 那为什么slave lag 为时大时小呢? 首先我们要了解MySQL 对于slave lag 的计算方式(sql/slave.cc ) - bool show_master_info(THD* thd, Master_info* mi)
- {
- /*省略*/
- /*
- Seconds_Behind_Master: if SQL thread is running and I/O thread is
- connected, we can compute it otherwise show NULL (i.e. unknown).
- */
- if ((mi->slave_running == MYSQL_SLAVE_RUN_CONNECT) &&
- mi->rli.slave_running)
- {
- long time_diff= ((long)(time(0) - mi->rli.last_master_timestamp)
- - mi->clock_diff_with_master);
- /*
- Apparently on some systems time_diff can be <0. Here are possible
- reasons related to MySQL:
- - the master is itself a slave of another master whose time is ahead.
- - somebody used an explicit SET TIMESTAMP on the master.
- Possible reason related to granularity-to-second of time functions
- (nothing to do with MySQL), which can explain a value of -1:
- assume the master's and slave's time are perfectly synchronized, and
- that at slave's connection time, when the master's timestamp is read,
- it is at the very end of second 1, and (a very short time later) when
- the slave's timestamp is read it is at the very beginning of second
- 2. Then the recorded value for master is 1 and the recorded value for
- slave is 2. At SHOW SLAVE STATUS time, assume that the difference
- between timestamp of slave and rli->last_master_timestamp is 0
- (i.e. they are in the same second), then we get 0-(2-1)=-1 as a result.
- This confuses users, so we don't go below 0: hence the max().
- last_master_timestamp == 0 (an "impossible" timestamp 1970) is a
- special marker to say "consider we have caught up".
- */
- protocol->store((longlong)(mi->rli.last_master_timestamp ?
- max(0, time_diff) : 0));
- }
- else
- {
- protocol->store_null();
- }
- /*省略*/
- }
查看新备库的server_id 主库上冲突的事务的server_id 备库上冲突事务的server_id 老的主库的server_id 解决方法 在新的备库更改server_id为冲突数据的server_id,等数据耗完毕,server_id改为原库的server_id。 读者朋友可以思考一下为什么在备库上执行更改server_id的操作? 对于MySQL 本身,可以加上一层判断,在复制结构中检查 log envent的server_id是否属于 复制结构中数据库的server_id,如果不是,则判断该事物属于复制风暴事物,予以抛弃 。 四 参考资料 [1] [2] [3]
转载地址:http://cmzdx.baihongyu.com/
你可能感兴趣的文章
Java IO流详尽解析
查看>>
Linux VSFTP服务器
查看>>
DHCP中继数据包互联网周游记
查看>>
Squid 反向代理服务器配置
查看>>
Java I/O操作
查看>>
Tomcat性能调优
查看>>
项目管理心得
查看>>
Android自学--一篇文章基本掌握所有的常用View组件
查看>>
灰度图像和彩色图像
查看>>
通过vb.net 和NPOI实现对excel的读操作
查看>>
TCP segmentation offload
查看>>
java数据类型
查看>>
数据结构——串的朴素模式和KMP匹配算法
查看>>
FreeMarker-Built-ins for strings
查看>>
验证DataGridView控件的数据输入
查看>>
POJ1033
查看>>
argparse - 命令行选项与参数解析(转)
查看>>
一维数组
查看>>
Linux学习笔记之三
查看>>
修改上一篇文章的node.js代码,支持默认页及支持中文
查看>>